Database Transaction¶
A database transaction groups CUBRID queries into a unit of consistency (for ensuring valid results in multi-user environment) and restore (for making the results of committed transactions permanent and ensuring that the aborted transactions are canceled in the database despite any failure, such as system failure). A transaction is a collection of one or more queries that access and update the database.
CUBRID allows multiple users to access the database simultaneously and manages accesses and updates to prevent inconsistency of the database. For example, if data is updated by one user, the changes made by this transaction are not seen to other users or the database until the updates are committed. This principle is important because the transaction can be rolled back without being committed.
You can delay permanent updates to the database until you are confident of the transaction result. Also, you can remove (ROLLBACK) all updates in the database if an unsatisfactory result or failure occurs in the application or computer system during the transaction. The end of the transaction is determined by the COMMIT WORK or ROLLBACK WORK statement. The COMMIT WORK statement makes all updates permanent while the ROLLBACK WORK statement cancels all updates entered in the transaction.
Transaction Commit¶
Updates that occurred in the database are not permanently stored until the COMMIT WORK statement is executed. "Permanently stored" means that storing the updates in the disk is completed; The WORK keyword can be omitted. In addition, other users of the database cannot see the updates until they are permanently applied. For example, when a new row is inserted into a class, only the user who inserted the row can access it until the database transaction is committed.
All locks obtained by the transaction are released after the transaction is committed.
COMMIT [WORK];
-- ;autocommit off
-- AUTOCOMMIT IS OFF
SELECT name, seats
FROM stadium WHERE code IN (30138, 30139, 30140);
name seats
=============================================
'Athens Olympic Tennis Centre' 3200
'Goudi Olympic Hall' 5000
'Vouliagmeni Olympic Centre' 3400
The following UPDATE statement changes three column values of seats from the stadium. To compare the results, check the current values and names before the update is done. Since csql runs in an autocommit mode by default, the following example is executed after setting the autocommit mode to off.
UPDATE stadium
SET seats = seats + 1000
WHERE code IN (30138, 30139, 30140);
SELECT name, seats FROM stadium WHERE code in (30138, 30139, 30140);
name seats
============================================
'Athens Olympic Tennis Centre' 4200
'Goudi Olympic Hall' 6000
'Vouliagmeni Olympic Centre' 4400
If the update is properly done, the changes can be permanently fixed. In this time, use the COMMIT WORK as below:
COMMIT [WORK];
Note
In CUBRID, an auto-commit mode is set by default for transaction management.
An auto-commit mode is a mode that commits or rolls back all SQL statements. The transaction is committed automatically if the SQL is executed successfully, or is rolled back automatically if an error occurs. Such auto commit modes are supported in any interfaces.
In CCI, PHP, ODBC and OLE DB interfaces, you can configure auto-commit mode by using CCI_DEFAULT_AUTOCOMMIT upon startup of an application. If configuration on broker parameter is omitted, the default value is set to ON. To change auto-commit mode, use the following functions by interface: cci_set_autocommit () for CCI interface and cubrid_set_autocommit () for PHP interface.
For session command (;AUtocommit) which enables auto-commit configuration in CSQL Interpreter, see Session Commands.
Transaction Rollback¶
The ROLLBACK WORK statement removes all updates to the database since the last transaction. The WORK keyword can be omitted. By using this statement, you can cancel incorrect or unnecessary updates before they are permanently applied to the database. All locks obtained during the transaction are released.
ROLLBACK [WORK];
The following example shows two commands that modify the definition and the row of the same table.
-- csql> ;autocommit off
CREATE TABLE code2 (
s_name CHAR(1),
f_name VARCHAR(10)
);
COMMIT;
ALTER TABLE code2 DROP s_name;
INSERT INTO code2 (s_name, f_name) VALUES ('D','Diamond');
ERROR: s_name is not defined.
The INSERT statement fails because the s_name column has been dropped in the definition of code. The data intended to be entered to the code table is correct, but the s_name column is wrongly removed. At this point, you can use the ROLLBACK WORK statement to restore the original definition of the code table.
ROLLBACK WORK;
Later, remove the s_name column by entering the ALTER TABLE again and modify the INSERT statement. The INSERT command must be entered again because the transaction has been aborted. If the database update has been done as intended, commit the transaction to make the changes permanent.
ALTER TABLE code DROP s_name;
INSERT INTO code (f_name) VALUES ('Diamond');
COMMIT WORK;
Savepoint and Partial Rollback¶
A savepoint is established during the transaction so that database changes made by the transaction are rolled back to the specified savepoint. Such operation is called a partial rollback. In a partial rollback, database operations (insert, update, delete, etc.) after the savepoint are rolled back, and transaction operations before it are not rolled back. The transaction can proceed with other operations after the partial rollback is executed. Or the transaction can be terminated with the COMMIT WORK or ROLLBACK WORK statement. Note that the savepoint does not commit the changes made by the transaction.
A savepoint can be created at a certain point of the transaction, and multiple savepoints can be used for a certain point. If a partial rollback is executed to a savepoint before the specified savepoint or the transaction is terminated with the COMMIT WORK or ROLLBACK WORK statement, the specified savepoint is removed. The partial rollback after the specified savepoint can be performed multiple times.
Savepoints are useful because intermediate steps can be created and named to control long and complicated utilities. For example, if you use a savepoint during the update operation, you don't need to perform all statements again when you made a mistake.
SAVEPOINT mark;
mark:
_ a SQL identifier
_ a host variable (starting with :)
If you make mark all the same value when you specify multiple savepoints in a single transaction, only the latest savepoint appears in the partial rollback. The previous savepoints remain hidden until the rollback to the latest savepoint is performed and then appears when the latest savepoint disappears after being used.
ROLLBACK [WORK] [TO [SAVEPOINT] mark] ;
mark:
_ a SQL identifier
_ a host variable (starting with :)
Previously, the ROLLBACK WORK statement canceled all database changes added since the latest transaction. The ROLLBACK WORK statement is also used for the partial rollback that rolls back the transaction changes after the specified savepoint.
If mark value is not given, the transaction terminates canceling all changes including all savepoints created in the transaction. If mark value is given, changes after the specified savepoint are canceled and the ones before it are remained.
The below example shows how to rollback a part of a transaction. Firstly, specify savepoints SP1, SP2.
-- csql> ;autocommit off
CREATE TABLE athlete2 (name VARCHAR(40), gender CHAR(1), nation_code CHAR(3), event VARCHAR(30));
INSERT INTO athlete2(name, gender, nation_code, event)
VALUES ('Lim Kye-Sook', 'W', 'KOR', 'Hockey');
SAVEPOINT SP1;
SELECT * from athlete2;
INSERT INTO athlete2(name, gender, nation_code, event)
VALUES ('Lim Jin-Suk', 'M', 'KOR', 'Handball');
SELECT * FROM athlete2;
SAVEPOINT SP2;
RENAME TABLE athlete2 AS sportsman;
SELECT * FROM sportsman;
ROLLBACK WORK TO SP2;
In the example above, the name change of the athlete2 table is rolled back by the partial rollback. The following example shows how to execute the query with the original name and examining the result.
SELECT * FROM athlete2;
DELETE FROM athlete2 WHERE name = 'Lim Jin-Suk';
SELECT * FROM athlete2;
ROLLBACK WORK TO SP2;
In the example above, deleting 'Lim Jin-Suk' is discarded by rollback work to SP2 command. The following example shows how to roll back to SP1.
SELECT * FROM athlete2;
ROLLBACK WORK TO SP1;
SELECT * FROM athlete2;
COMMIT WORK;
Cursor Holdability¶
Cursor holdability is when an application holds the record set of the SELECT query result to fetch the next record even after performing an explicit commit or an automatic commit. In each application, cursor holdability can be specified as Connection level or Statement level. If it is not specified, the cursor is held by default. Therefore, HOLD_CURSORS_OVER_COMMIT is the default setting.
The following code shows how to set cursor holdability in JDBC:
// set cursor holdability at the connection level
conn.setHoldability(ResultSet.HOLD_CURSORS_OVER_COMMIT);
// set cursor holdability at the statement level which can override the connection
PreparedStatement pStmt = conn.prepareStatement(sql,
ResultSet.TYPE_SCROLL_SENSITIVE,
ResultSet.CONCUR_UPDATABLE,
ResultSet.HOLD_CURSORS_OVER_COMMIT);
To set cursor holdability to close the cursor when a transaction is committed, set ResultSet.CLOSE_CURSORS_AT_COMMIT, instead of ResultSet.HOLD_CURSORS_OVER_COMMIT, in the above example.
The default setting for applications that were developed based on CCI is to hold the cursor. If the cursor is set to 'not to hold a cursor' at connection level and you want to hold the cursor, define the CCI_PREPARE_HOLDABLE flag while preparing a query. The default setting for CCI drivers (PHP, PDO, ODBC, OLE DB, ADO.NET, Perl, Python, Ruby) is to hold the cursor. To check whether a driver supports the cursor holdability setting, refer to the PREPARE function of the driver.
Note
- Note that versions lower than CUBRID 9.0 do not support cursor holdability. The default setting of those versions is to close all cursors at commit.
- CUBRID currently does not support ResultSet.HOLD_CURSORS_OVER_COMMIT in java.sql.XAConnection interface.
Cursor-related Operation at Transaction Commit
When a transaction is committed, all statements and result sets that are closed are released even if you have set cursor holdability. After that, when the result sets are used for another transaction, some or all of the result sets should be closed as required.
When a transaction is rolled back, all result sets are closed. This means that all result sets held in the previous transaction are closed because you have set cursor holdability.
rs1 = stmt.executeQuery(sql1);
conn.commit();
rs2 = stmt.executeQuery(sql2);
conn.rollback(); // result sets rs1 and rs2 are closed and it will not be available to use them.
When the Result Sets are Closed
The result sets that hold the cursor are closed in the following cases:
- Driver closes the result set, i.e. rs.close()
- Driver closes the statement, i.e. stmt.close()
- Driver disconnects the connection.
- Transaction aborts, for instance, application explicitly calls rollback(), auto rollback due to a query failure under auto-commit mode.
Relationship with CAS
When the connection between an application and the CAS is closed, all result sets are automatically closed even if you have set cursor holdability in the application. The setting value of KEEP_CONNECTION, the broker parameter, affects cursor holdability of the result set.
- KEEP_CONNECTION = ON: Cursor holdability is not affected.
- KEEP_CONNECTION = AUTO: The CAS cannot be restarted while the result set with cursor holdability is open.
Warning
Usage of memory will increase in the status of result set opened. Thus, you should close the result set after completion.
Note
Note that CUBRID versions lower than 9.0 do not support cursor holdability and the cursor is automatically closed when a transaction is committed. Therefore, the recordset of the SELECT query result is not kept.
Database Concurrency¶
If there are multiple users with read and write authorization to a database, possibility exists that more than one user will access the database simultaneously. Controlling access and update in multi-user environment is essential to protect database integrity and ensure that users and transactions should have accurate and consistent data. Without appropriate control, data could be updated incorrectly in the wrong order.
The transaction must ensure database concurrency, and each transaction must guarantee appropriate results. When multiple transactions are being executed at once, an event in transaction T1 should not affect an event in transaction T2. This means isolation. Transaction isolation level is the degree to which a transaction is separated from all other concurrent transactions. The higher isolation level means the lower interference from other transactions. The lower isolation level means the higher the concurrency. A database determines whether which lock is applied to tables and records based on these isolation levels. Therefore, can control the level of consistency and concurrency specific to a service by setting appropriate isolation level.
The read operations that allow interference between transactions with isolation levels are as follows:
- Dirty read : A transaction T2 can read D' before a transaction T1 updates data D to D' and commits it.
- Non-repeatable read : A transaction T1 can read changed value, if a transaction T2 updates or deletes data and commits while data is retrieved in the transaction T1 multiple times.
- Phantom read : A transaction T1 can read E, if a transaction T2 inserts new record E and commits while data is retrieved in the transaction T1 multiple times.
Based on these interferences, the SQL standard defines four levels of transaction isolation:
- READ UNCOMMITTED allows dirty read, unrepeatable read and phantom read.
- READ COMMITTED does not allow dirty read but allows unrepeatable read and phantom read.
- REPEATABLE READ does not allow dirty read and unrepeatable read but allows phantom read.
- SERIALIZABLE does not allow interrupts between transactions when doing read operation.
Isolation Levels Provided by CUBRID
On the below table, the number wrapped with parenthesis right after the isolation level name is a number which can be used instead of the isolation level name when setting an isolation level.
You can set an isolation level by using the SET TRANSACTION ISOLATION LEVEL statement or system parameters provided by CUBRID. For details, see Concurrency/Lock-Related Parameters.
(O: YES, X: NO)
| CUBRID Isolation Level (isolation_level) | DIRTY READ | UNREPEATABLE READ | PHANTOM READ | Schema Changes of the Table Being Retrieved |
|---|---|---|---|---|
| SERIALIZABLE Isolation Level (6) | X | X | X | X |
| REPEATABLE READ Isolation Level (5) | X | X | O | X |
| READ COMMITTED Isolation Level (4) | X | O | O | X |
The default value of CUBRID isolation level is READ COMMITTED Isolation Level.
Multiversion Concurrency Control¶
CUBRID previous versions managed isolation levels using the well known two phase locking protocol. In this protocol, a transaction obtains a shared lock before it reads an object, and an exclusive lock before it updates the object so that conflicting operations are not executed simultaneously. If transaction T1 requires a lock, the system checks if the requested lock conflicts with the existing one. If it does, transaction T1 enters a standby state and delays the lock. If another transaction T2 releases the lock, transaction T1 resumes and obtains it. Once the lock is released, the transaction do not require any new locks.
CUBRID 10.0 replaced the two phase locking protocol with a Multiversion Concurrency Control (MVCC) protocol. Unlike two phase locking, MVCC does not block readers to access objects being modified by concurrent transactions. MVCC duplicates rows, creating multiple versions on each update. Never blocking readers is important for workloads involving mostly value reads from the database, commonly used in read-world scenarios. Exclusive locks are still required before updating objects.
MVCC is also known for providing point in time consistent view of the database and for being particularly adept at implementing true snapshot isolation with less performance costs than other methods of concurrency.
Versioning, visibility and snapshot¶
MVCC maintains multiple versions for each database row. Each version is marked by its inserter and deleter with MVCCID's - unique identifiers for writer transactions. These markers are useful to identify the author of a change and to place the change on a timeline.
When a transaction T1 inserts a new row, it creates its first version and sets its unique identifier MVCCID1 as insert id. The MVCCID is stored as meta-data in record header:
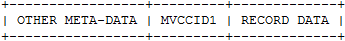
Until T1 commits, other transactions should not see this row. The MVCCID helps identifying the authors of database changes and place them on a time line, so others can know if the change is valid or not. In this case, anyone checking this row find the MVCCID1, find out that the owner is still active, hence the row must be (still) invisible.
After T1 commits, a new transaction T2 finds the row and decides to remove it. T2 does not remove this version, allowing others to access it, instead it gets an exclusive lock, to prevent others from changing it, and marks the version as deleted. It adds another MVCCID so others can identify the deleter:

If T2 decides instead to update one of the record values, it must create a new version. Both versions are marked with transaction MVCCID, old version for delete and new version for insert. Old version also stores a link to the location of new version, and the row representations looks like this:

Currently, only T2 can see second row version, while all other transaction will continue to access the first version. The property of a version to be seen or not to be seen by running transactions is called visibility. The visibility property is relative to each transaction, some can consider it true, whereas others can consider it false.
A transaction T3 that starts after T2 executes row update, but before T2 commits, will not be able to see its new version, not even after T2 commits. The visibility of one version towards T3 depends on the state of its inserter and deleter when T3 started and preserves its status for the lifetime of T3.
As a matter of fact, the visibility of all versions in database towards on transaction does not depend on the changes that occur after transaction is started. Moreover, any new version added is also ignored. Consequently, the set of all visible versions in the database remains unchanged and form the snapshot of the transaction. Hence, snapshot isolation is provided by MVCC and it is a guarantee that all read queries made in a transaction see a consistent view of the database.
In CUBRID 10.0, snapshot is a filter of all invalid MVCCID's. An MVCCID is invalid if it is not committed before the snapshot is taken. To avoid updating the snapshot filter whenever a new transaction starts, the snapshot is defined using two border MVCCID's: the lowest active MVCCID and the highest committed MVCCID. Only a list of active MVCCID values between the border is saved. Any transaction starting after snapshot is guaranteed to have an MVCCID bigger than highest committed and is automatically considered invalid. Any MVCCID below lowest active must be committed and is automatically considered valid.
The snapshot filter algorithm that decides a version visibility queries the MVCCID markers used for insert and delete:
| Delete MVCCID | |||
| Valid | Invalid | ||
| Insert MVCCID | Valid | Not visible | Visible |
| Invalid | Impossible | Not visible | |
Table explained:
- Valid insert MVCCID, valid delete MVCCID: Version was inserted and deleted (and both committed) before snapshot, hence it is not visible.
- Valid insert MVCCID, invalid delete MVCCID: Version was inserted and committed, but it was not deleted or it was recently deleted, hence it is visible.
- Invalid insert MVCCID, invalid delete MVCCID: Inserter did not commit before snapshot, and record is not deleted or delete was also not committed, hence version is not visible.
- Invalid insert MVCCID, valid delete MVCCID: Inserter did not commit and deleter did - impossible case. If deleter is not the same as inserter, it could not see the version, and if it is, both insert and delete MVCCID must be valid or invalid.
Let's see how snapshot works (REPEATABLE READ isolation will be used to keep same snapshot during entire transaction):
Example 1: Inserting a new row
| session 1 | session 2 |
|---|---|
csql> ;autocommit off
AUTOCOMMIT IS OFF
csql> set transaction isolation level REPEATABLE READ;
Isolation level set to:
REPEATABLE READ
|
csql> ;autocommit off
AUTOCOMMIT IS OFF
csql> set transaction isolation level REPEATABLE READ;
Isolation level set to:
REPEATABLE READ
|
csql> CREATE TABLE tbl(host_year integer, nation_code char(3));
csql> COMMIT WORK;
|
|
-- insert a row without committing
csql> INSERT INTO tbl VALUES (2008, 'AUS');
-- current transaction sees its own changes
csql> SELECT * FROM tbl;
host_year nation_code
===================================
2008 'AUS'
|
|
-- this snapshot should not see uncommitted row
csql> SELECT * FROM tbl;
There are no results.
|
|
csql> COMMIT WORK;
|
|
-- even though inserter did commit, this snapshot still can't see the row
csql> SELECT * FROM tbl;
There are no results.
-- commit to start a new transaction with a new snapshot
csql> COMMIT WORK;
-- the new snapshot should see committed row
csql> SELECT * FROM tbl;
host_year nation_code
===================================
2008 'AUS'
|
Example 2: Deleting a row
| session 1 | session 2 |
|---|---|
csql> ;autocommit off
AUTOCOMMIT IS OFF
csql> set transaction isolation level REPEATABLE READ;
Isolation level set to:
REPEATABLE READ
|
csql> ;autocommit off
AUTOCOMMIT IS OFF
csql> set transaction isolation level REPEATABLE READ;
Isolation level set to:
REPEATABLE READ
|
csql> CREATE TABLE tbl(host_year integer, nation_code char(3));
csql> INSERT INTO tbl VALUES (2008, 'AUS');
csql> COMMIT WORK;
|
|
-- delete the row without committing
csql> DELETE FROM tbl WHERE nation_code = 'AUS';
-- this transaction sees its own changes
csql> SELECT * FROM tbl;
There are no results.
|
|
-- delete was not committed, so the row is visible to this snapshot
csql> SELECT * FROM tbl;
host_year nation_code
===================================
2008 'AUS'
|
|
csql> COMMIT WORK;
|
|
-- delete was committed, but the row is still visible to this snapshot
csql> SELECT * FROM tbl;
host_year nation_code
===================================
2008 'AUS'
-- commit to start a new transaction with a new snapshot
csql> COMMIT WORK;
-- the new snapshot can no longer see deleted row
csql> SELECT * FROM tbl;
There are no results.
|
Example 3: Updating a row
| session 1 | session 2 |
|---|---|
csql> ;autocommit off
AUTOCOMMIT IS OFF
csql> set transaction isolation level REPEATABLE READ;
Isolation level set to:
REPEATABLE READ
|
csql> ;autocommit off
AUTOCOMMIT IS OFF
csql> set transaction isolation level REPEATABLE READ;
Isolation level set to:
REPEATABLE READ
|
csql> CREATE TABLE tbl(host_year integer, nation_code char(3));
csql> INSERT INTO tbl VALUES (2008, 'AUS');
csql> COMMIT WORK;
|
|
-- delete the row without committing
csql> UPDATE tbl SET host_year = 2012 WHERE nation_code = 'AUS';
-- this transaction sees new version, host_year = 2012
csql> SELECT * FROM tbl;
host_year nation_code
===================================
2012 'AUS'
|
|
-- update was not committed, so this snapshot sees old version
csql> SELECT * FROM tbl;
host_year nation_code
===================================
2008 'AUS'
|
|
csql> COMMIT WORK;
|
|
-- update was committed, but this snapshot still sees old version
csql> SELECT * FROM tbl;
host_year nation_code
===================================
2008 'AUS'
-- commit to start a new transaction with a new snapshot
csql> COMMIT WORK;
-- the new snapshot can see new version, host_year = 2012
csql> SELECT * FROM tbl;
host_year nation_code
===================================
2012 'AUS'
|
Example 4: Different versions can be visible to different transactions
| session 1 | session 2 | session 3 |
|---|---|---|
csql> INSERT INTO tbl VALUES (2008, 'AUS');
csql> COMMIT WORK;
|
||
-- update row
csql> UPDATE tbl SET host_year = 2012 WHERE nation_code = 'AUS';
csql> SELECT * FROM tbl;
host_year nation_code
===================================
2012 'AUS'
|
csql> SELECT * FROM tbl;
host_year nation_code
===================================
2008 'AUS'
|
|
csql> COMMIT WORK;
|
||
csql> UPDATE tbl SET host_year = 2016 WHERE nation_code = 'AUS';
csql> SELECT * FROM tbl;
host_year nation_code
===================================
2016 'AUS'
|
csql> SELECT * FROM tbl;
host_year nation_code
===================================
2008 'AUS'
|
csql> SELECT * FROM tbl;
host_year nation_code
===================================
2012 'AUS'
|
VACUUM¶
Creating new versions for each update and keeping old versions on delete could lead to unlimited database size growth, definitely a major issue for a database. Therefore, a clean up system is necessary, to remove obsolete data and reclaim the occupied space for reuse.
Each row version goes through same stages:
- newly inserted, not committed, visible only to its inserter.
- committed, invisible to preceding transactions, visible to future transactions.
- deleted, not committed, visible to other transactions, invisible to the deleter.
- committed, still visible to preceding transactions, invisible to future transactions.
- invisible to all active transactions.
- removed from database.
The role of the clean up system is to get versions from stage 5 to 6. This system is called VACUUM in CUBRID.
VACUUM system was developed with the guidance of three principles:
- VACUUM must be correct and complete. VACUUM should never remove data still visible to some and it should not miss any obsolete data.
- VACUUM must be discreet. Since clean-up process changes database content, there may be some interference in the activity of live transactions, but it must be kept to the minimum possible.
- VACUUM must be fast and efficient. If VACUUM is too slow and if it starts lagging, the database state can deteriorate, thus the overall performance can be affected.
With these principles in mind, VACUUM implementation uses existing recovery logging, because:
- The address is kept among recovery data for both heap and index changes. This allows VACUUM go directly to target, rather than scanning the database.
- Processing log data rarely interferes with the work of active workers.
Log recovery was adapted to VACUUM needs by adding MVCCID information to logged data. VACUUM can decide based on MVCCID if the log entry is ready to be processed. MVCCID's that are still visible to active transactions cannot be processed. In due time, each MVCCID becomes old enough and all changes using the MVCCID become invisible.
Each transaction keeps the oldest MVCCID it considers active. The oldest MVCCID considered active by all running transactions is determined by the smallest oldest MVCCID of all transactions. Anything below this value is invisible and VACUUM can clean.
VACUUM Parallel Execution¶
According to the third principle of VACUUM it must be fast and it should not fall behind active workers. It is obvious that one thread cannot handle all the VACUUM works if system workload is heavy, thus it had to be parallelized.
To achieve parallelization, the log data was split into fixed size blocks. Each block generates one vacuum job, when the time is right (the most recent MVCCID can be vacuumed, which means all logged operations in the block can be vacuumed). Vacuum jobs are picked up by multiple VACUUM Workers that clean the database based on relevant log entries found in the log block. The tracking of log blocks and generating vacuum jobs is done by the VACUUM Master.
VACUUM Data¶
Aggregated data on log blocks is stored in vacuum data file. Since the vacuum job generated by an operations occurs later in time, the data must be saved until the job can be executed, and it must also be persistent even if the server crashes. No operation is allowed to leak and not be vacuumed. If the server crashes, some jobs may be executed twice, which is preferable to not being executed at all.
After a job has been successfully executed, the aggregated data on the processed log block is removed.
Aggregated log block data is not added directly to vacuum data. A latch-free buffer is used to avoid synchronizing active working threads (which generate the log blocks and their aggregated data) with the vacuum system. VACUUM Master wakes up periodically, dumps everything in buffer to vacuum data, removes data already process and generates new jobs (if available).
VACUUM jobs¶
Vacuum job execution steps:
- Log pre-fetch. Vacuum master or workers pre-fetch log pages to be processed by the job.
- Repeat for each log record:
- Read log record.
- Check dropped file. If the log record points to dropped file, proceed to next log record.
- Execute index vacuum and collect heap OID's
- If log record belongs to index, execute vacuum immediately.
- If log record belongs to heap, collect OID to be vacuumed later.
- Execute heap vacuum based on collected OID's.
- Complete job. Mark the job as completed in vacuum data.
Several measures were taken to ease log page reading and to optimize vacuum execution.
Tracking dropped files¶
When a transaction drops a table or an index, it usually locks the affected table(s) and prevents others from accessing it. Opposed to active workers, VACUUM Workers are not allowed to use locking system, for two reasons: interference with active workers must be kept to the minimum, and VACUUM system is never supposed to stop as long as it has data to clean. Moreover, VACUUM is not allowed to skip any data that needs cleaning. This has two consequences:
- VACUUM doesn't stop from cleaning a file belonging to a dropped table or a dropped index until the dropper commits. Even if a transaction drops a table, its file is not immediately destroyed and it can still be accessed. The actual destruction is postponed until after commit.
- Before the actual file destruction, VACUUM system must be notified. The dropper sends a notification to VACUUM system and then waits for the confirmation. VACUUM works on very short iterations and it checks for new dropped files frequently, so the dropper doesn't have to wait for a long time.
After a file is dropped, VACUUM will ignore all found log entries that belong to the file. The file identifier, paired with an MVCCID that marks the moment of drop, is stored in a persistent file until VACUUM decides it is safe to remove it (the decision is based on the smallest MVCCID not yet vacuumed).
Lock Protocol¶
In the two-phase locking protocol, a transaction obtains a shared lock before it reads an object, and an exclusive lock before it updates the object so that conflicting operations are not executed simultaneously. The MVCC locking protocol, which is now used by CUBRID, does not require shared locks before reading rows (however intent shared lock on table object is still used to read its rows). If transaction T1 requires a lock, CUBRID checks if the requested lock conflicts with the existing one. If it does, transaction T1 enters a standby state and delays the lock. If another transaction T2 releases the lock, transaction T1 resumes and obtains it. Once the lock is released, the transaction do not acquire any new locks.
Granularity Locking¶
CUBRID uses a granularity locking protocol to decrease the number of locks. In the granularity locking protocol, a database can be modelled as a hierarchy of lockable units: row lock, table lock and database lock. Coarser locks have more granular locks.
If the locking granularities overlap, effects of a finer granularity are propagated in order to prevent conflicts. That is, if a shared lock is required on an instance of a table, an intent shared lock will be set on the table. If an exclusive lock is required on an instance of a table, an intent exclusive lock will be set on the table. An intent shared lock on a table means that a shared lock can be set on an instance of the table. An intent exclusive lock on a table means that a shared/exclusive lock can be set on an instance of the table. That is, if an intent shared lock on a table is allowed in one transaction, another transaction cannot obtain an exclusive lock on the table (for example, to add a new column). However, the second transaction may obtain a shared lock on the table. If an intent exclusive lock on the table is allowed in one transaction, another transaction cannot obtain a shared lock on the table (for example, a query on an instance of the tables cannot be executed because it is being changed).
A mechanism called lock escalation is used to limit the number of locks being managed. If a transaction has more than a certain number of locks (a number which can be changed by the lock_escalation system parameter), the system begins to require locks at the next higher level of granularity. This escalates the locks to a coarser level of granularity. CUBRID performs lock escalation when no transactions have a higher level of granularity in order to avoid a deadlock caused by lock conversion.
Lock Mode Types And Compatibility¶
CUBRID determines the lock mode depending on the type of operation to be performed by the transaction, and determines whether or not to share the lock depending on the mode of the lock preoccupied by another transaction. Such decisions concerning the lock are made by the system automatically. Manual assignment by the user is not allowed. To check the lock information of CUBRID, use the cubrid lockdb db_name command. For details, see lockdb.
Shared lock (shared lock, S_LOCK, no longer used with MVCC protocol)
This lock is obtained before the read operation is executed on the object.
It can be obtained by multiple transactions for the same object. At this time, transaction T2 and T3 can perform the read operation on the object concurrently, but not the update operation.
Note
- Shared locks are rarely used in CUBRID 10.0, because of MVCC. It is still used, mostly in internal database operations, to protect rows or index keys from being modified.
Exclusive lock (exclusive lock, X_LOCK)
This lock is obtained before the update operation is executed on the object.
It can only be obtained by one transaction. Transaction T1 obtains the exclusive lock first before it performs the update operation on a certain object X, and does not release it until transaction T1 is committed even after the update operation is completed. Therefore, transaction T2 and T3 cannot perform the read operation as well on X before transaction T1 releases the exclusive lock.
Intent lock
This lock is set inherently in a higher-level object than a certain object to protect the lock on the object of a certain level.
For example, when a shared lock is requested for a certain row, prevent a situation from occurring in which the table is locked by another transaction by setting the intent shared lock as well on the table at the higher level in hierarchy. Therefore, the intent lock is not set on rows at the lowest level, but is set on higher-level objects. The types of intent locks are as follows:
Intent shared lock (IS_LOCK)
If the intent shared lock is set on the table, which is the higher-level object, as a result of the shared lock set on a certain row, another transaction cannot perform operations such as changing the schema of the table (e.g. adding a column or changing the table name) or updating all rows. However updating some rows or viewing all rows is allowed.
Intent exclusive lock (IX_LOCK)
If the intent exclusive lock is set on the table, which is the higher-level object, as a result of the exclusive lock set on a certain row, another transaction cannot perform operations such as changing the schema of the table, updating or viewing all rows. However updating some rows is allowed.
Shared with intent exclusive lock(SIX_LOCK)
This lock is set on the higher-level object inherently to protect the shared lock set on all objects at the lower hierarchical level and the intent exclusive lock on some object at the lower hierarchical level.
Once the shared intent exclusive lock is set on a table, another transaction cannot change the schema of the table, update all/some rows or view all rows. However, viewing some rows is allowed.
Schema Lock
A schema lock is acquired when executing DDL work.
Schema stability lock, SCH_S_LOCK
This lock is acquired during compiling a query and it guarantees that the schema which is included in this query is not changed.
Schema modification lock, SCH_M_LOCK
This lock is acquired during running DDL(ALTER/CREATE/DROP) and it protects that other transactions access the modified schema.
Some DDL operations like ALTER, CREATE INDEX do not acquire SCH_M_LOCK directly. For example, CUBRID operates type checking about filtering expression when you create a filtered index; during this term, the lock which is kept to the target table is SCH_S_LOCK like other type checking operations. The lock is then upgraded to SIX_LOCK (other transactions are prevented from modifying target table rows, but they can continue reading them), and finally SCH_M_LOCK is requested to change the table schema. The method has a strength to increase the concurrency by allowing other transaction's operation during DDL operation's compilation and execution.
However, it also has a weakness not to avoid a deadlock when DDL operations are operated at the same table at the same time. A deadlock case by loading indexes is as follows.
T1 T2 CREATE INDEX i_t_i on t(i) WHERE i > 0;
CREATE INDEX i_t_j on t(j) WHERE j > 0;
SCH_S_LOCK during checking types of "i > 0" case. SCH_S_LOCK during checking types of "j > 0" case."j > 0" SIX_LOCK during index loading. requesting SIX_LOCK but waiting T1's SIX_LOCK is released requesting SCH_M_LOCK but waiting T2's SCH_S_LOCK is released
Note
This is a summarized description about locking.
- There are row(instance) and schema(class) about objects of locking targets. The locks grouped by the type of objects they're used:
- row locks: S_LOCK, X_LOCK
- intention/schema locks: IX_LOCK, IS_LOCK, SIX_LOCK, SCH_S_LOCK, SCH_M_LOCK
- Row locks and intention/schema locks affect each other.
The following table briefly shows the lock compatibility between the locks described above. Compatibility means that the lock requester can obtain a lock while the lock holder is keeping the lock obtained for a certain object.
Lock Compatibility
- NULL: The status that any lock exists.
(O: TRUE, X: FALSE)
| Lock holder | |||||||||
| NULL | SCH-S | IS | S | IX | SIX | X | SCH-M | ||
| Lock requester | NULL | O | O | O | O | O | O | O | O |
| SCH-S | O | O | O | O | O | O | O | O | |
| IS | O | O | O | O | O | O | X | X | |
| S | O | O | O | O | X | X | X | X | |
| IX | O | O | O | X | O | X | X | X | |
| SIX | O | O | O | X | X | X | X | X | |
| X | O | O | X | X | X | X | X | X | |
| SCH-M | O | X | X | X | X | X | X | X | |
Lock Transformation Table
- NULL: The status that any lock exists.
| Granted lock mode | |||||||||
| NULL | SCH-S | IS | S | IX | SIX | X | SCH-M | ||
| Requested lock mode | NULL | NULL | SCH-S | IS | S | IX | SIX | X | SCH-M |
| SCH-S | SCH-S | SCH-S | IS | S | IX | SIX | X | SCH-M | |
| IS | IS | IS | IS | S | IX | SIX | X | SCH-M | |
| S | S | S | S | S | SIX | SIX | X | SCH-M | |
| IX | IX | IX | IX | SIX | IX | SIX | X | SCH-M | |
| SIX | SIX | SIX | SIX | SIX | SIX | SIX | X | SCH-M | |
| X | X | X | X | X | X | X | X | SCH-M | |
| SCH-M | SCH-M | SCH-M | SCH-M | SCH-M | SCH-M | SCH-M | SCH-M | SCH-M | |
Examples using locks¶
For next few examples, REPEATABLE READ(5) isolation level will be used. READ COMMITTED has different rules for updating rows and will be presented in next section (reference here). The examples will make use of lockdb utility to show existing locks.
Locking example: For next example REPEATABLE READ(5) isolation will be used and it will prove that read and write on same row are not blocked. Also conflicting updates will be tried, where the second updater is blocked. When transaction T1 commits, T2 is unblocked but update is not permitted because of isolation level restrictions. If T1 would rollback, then T2 can proceed with its update.
| T1 | T2 | Description |
|---|---|---|
csql> ;au off
csql> SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
|
csql> ;au off
csql> SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
|
AUTOCOMMIT OFF and REPEATABLE READ |
csql> CREATE TABLE tbl(a INT PRIMARY KEY, b INT);
csql> INSERT INTO tbl
VALUES (10, 10),
(30, 30),
(50, 50),
(70, 70);
csql> COMMIT;
|
||
csql> UPDATE tbl SET a = 90 WHERE a = 10;
|
First version of row where a = 10 is locked and updated. A new version where row has a = 90 is created and also locked. cubrid lockdb:
OID = 0| 623| 4
Object type: Class = tbl.
Total mode of holders = IX_LOCK,
Total mode of waiters = NULL_LOCK.
Num holders= 1, Num blocked-holders= 0,
Num waiters= 0
LOCK HOLDERS:
Tran_index = 1, Granted_mode = IX_LOCK
OID = 0| 650| 5
Object type: Instance of class ( 0| 623| 4) = tbl.
MVCC info: insert ID = 5, delete ID = missing.
Total mode of holders = X_LOCK,
Total mode of waiters = NULL_LOCK.
Num holders= 1, Num blocked-holders= 0,
Num waiters= 0
LOCK HOLDERS:
Tran_index = 1, Granted_mode = X_LOCK
OID = 0| 650| 1
Object type: Instance of class ( 0| 623| 4) = tbl.
MVCC info: insert ID = 4, delete ID = 5.
Total mode of holders = X_LOCK,
Total mode of waiters = NULL_LOCK.
Num holders= 1, Num blocked-holders= 0,
Num waiters= 0
LOCK HOLDERS:
Tran_index = 1, Granted_mode = X_LOCK
|
|
csql> SELECT * FROM tbl WHERE a <= 20;
a b
==========================
10 10
|
Transaction T2 reads all rows where a <= 20. Since T1 did not commit its update, T2 will continue to see the row with a = 10 and will not lock it.: cubrid lockdb:
OID = 0| 623| 4
Object type: Class = tbl.
Total mode of holders = IX_LOCK,
Total mode of waiters = NULL_LOCK.
Num holders= 2, Num blocked-holders= 0,
Num waiters= 0
LOCK HOLDERS:
Tran_index = 1, Granted_mode = IX_LOCK
Tran_index = 2, Granted_mode = IS_LOCK
|
|
csql> UPDATE tbl
SET a = a + 100
WHERE a <= 20;
|
Transaction T2 now tries to update all rows having a <= 20. This means T2 will upgrade its lock on class to IX_LOCK and will also try to update the row = 10 by first locking it. However, T1 has locked it already, so T2 will be blocked. cubrid lockdb:
OID = 0| 623| 4
Object type: Class = tbl.
Total mode of holders = IX_LOCK,
Total mode of waiters = NULL_LOCK.
Num holders= 2, Num blocked-holders= 0,
Num waiters= 0
LOCK HOLDERS:
Tran_index = 1, Granted_mode = IX_LOCK
Tran_index = 2, Granted_mode = IX_LOCK
OID = 0| 650| 5
Object type: Instance of class ( 0| 623| 4) = tbl.
MVCC info: insert ID = 5, delete ID = missing.
Total mode of holders = X_LOCK,
Total mode of waiters = NULL_LOCK.
Num holders= 1, Num blocked-holders= 0,
Num waiters= 0
LOCK HOLDERS:
Tran_index = 1, Granted_mode = X_LOCK
OID = 0| 650| 1
Object type: Instance of class ( 0| 623| 4) = tbl.
MVCC info: insert ID = 4, delete ID = 5.
Total mode of holders = X_LOCK,
Total mode of waiters = X_LOCK.
Num holders= 1, Num blocked-holders= 0,
Num waiters= 1
LOCK HOLDERS:
Tran_index = 1, Granted_mode = X_LOCK
LOCK WAITERS:
Tran_index = 2, Blocked_mode = X_LOCK
|
|
csql> COMMIT;
|
T1's locks are released. | |
ERROR: Serializable conflict due
to concurrent updates
|
T2 is unblocked and will try to update the object T1 already updated. This is however not allowed in REPEATABLE READ isolation level and an error is thrown. |
Locking to protect unique constraint¶
Two phase locking protocol in older CUBRID versions used index key locks to protect unique constraints and higher isolation restrictions. In CUBRID 10.0, key locking was removed. Isolation level restrictions are solved by MVCC snapshot, however unique constraint still needed some type of protection.
With MVCC, unique index can keep multiple versions at the same time, similarly to rows, each visible to different transactions. One is the last version, while the other versions are kept temporarily until they become invisible and can be removed by VACUUM. The rule to protect unique constraint is that all transactions trying to modify a key has to lock key's last existing version.
The below example uses REPEATABLE READ isolation to show the way locking prevents unique constraint violations.
| T1 | T2 | Description |
|---|---|---|
csql> ;au off
csql> SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
|
csql> ;au off
csql> SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
|
AUTOCOMMIT OFF and REPEATABLE READ |
csql> CREATE TABLE tbl(a INT PRIMARY KEY, b INT);
csql> INSERT INTO tbl
VALUES (10, 10),
(30, 30),
(50, 50),
(70, 70);
csql> COMMIT;
|
||
csql> INSERT INTO tbl VALUES (20, 20);
|
T1 inserts a new row into table and also locks it. The key 20 is therefore protected. | |
INSERT INTO tbl VALUES (20, 120);
|
T2 also inserts a new row into table and locks it. However, when it tries to insert it in primary key, it discovers key 20 already exists. T2 has to lock existing object, that T1 inserted, and is blocked until T1 commits. cubrid lockdb:
OID = 0| 623| 4
Object type: Class = tbl.
Total mode of holders = IX_LOCK,
Total mode of waiters = NULL_LOCK.
Num holders= 2, Num blocked-holders= 0,
Num waiters= 0
LOCK HOLDERS:
Tran_index = 1, Granted_mode = IX_LOCK
Tran_index = 2, Granted_mode = IX_LOCK
OID = 0| 650| 5
Object type: Instance of class ( 0| 623| 4) = tbl.
MVCC info: insert ID = 5, delete ID = missing.
Total mode of holders = X_LOCK,
Total mode of waiters = X_LOCK.
Num holders= 1, Num blocked-holders= 0,
Num waiters= 1
LOCK HOLDERS:
Tran_index = 1, Granted_mode = X_LOCK
LOCK WAITERS:
Tran_index = 1, Blocked_mode = X_LOCK
OID = 0| 650| 6
Object type: Instance of class ( 0| 623| 4) = tbl.
MVCC info: insert ID = 6, delete ID = missing.
Total mode of holders = X_LOCK,
Total mode of waiters = NULL_LOCK.
Num holders= 1, Num blocked-holders= 0,
Num waiters= 0
LOCK HOLDERS:
Tran_index = 2, Granted_mode = X_LOCK
|
|
COMMIT;
|
T1's locks are released. | |
ERROR: Operation would have caused
one or more unique constraint violations.
INDEX pk_tbl_a(B+tree: 0|186|640)
ON CLASS tbl(CLASS_OID: 0|623|4).
key: 20(OID: 0|650|6).
|
T2 is unlocked, finds the key has been committed and throws unique constraint violation error. |
Transaction Deadlock¶
A deadlock is a state in which two or more transactions wait at once for another transaction's lock to be released. CUBRID resolves the problem by rolling back one of the transactions because transactions in a deadlock state will hinder the work of another transaction. The transaction to be rolled back is usually the transaction which has made the least updates; it is usually the one that started more recently. As soon as a transaction is rolled back, the lock held by the transaction is released and other transactions in a deadlock are permitted to proceed.
It is impossible to predict such deadlocks, but it is recommended that you reduce the range to which lock is applied by setting the index, shortening the transaction, or setting the transaction isolation level as low in order to decrease such occurrences.
Note that if you configure the value of error_log_level, which indicates the severity level, to NOTIFICATION, information on lock is stored in error log file of server upon deadlock occurrences.
Compared to older versions, CUBRID 10.0 no longer uses index key locking to read and write in index, thus deadlock occurrences have been greatly reduced. Another reason that deadlocks do not occur as often is that reading a range in index could lock many objects with high isolation levels in previous CUBRID versions, whereas CUBRID 10.0 uses no locks.
However, deadlocks are still possible when two transaction update same objects, but in a different order.
Example
| session 1 | session 2 |
|---|---|
csql> ;autocommit off
AUTOCOMMIT IS OFF
csql> set transaction isolation level REPEATABLE READ;
Isolation level set to:
REPEATABLE READ
|
csql> ;autocommit off
AUTOCOMMIT IS OFF
csql> set transaction isolation level REPEATABLE READ;
Isolation level set to:
REPEATABLE READ
|
csql> CREATE TABLE lock_tbl(host_year INTEGER,
nation_code CHAR(3));
csql> INSERT INTO lock_tbl VALUES (2004, 'KOR');
csql> INSERT INTO lock_tbl VALUES (2004, 'USA');
csql> INSERT INTO lock_tbl VALUES (2004, 'GER');
csql> INSERT INTO lock_tbl VALUES (2008, 'GER');
csql> COMMIT;
|
|
csql> DELETE FROM lock_tbl WHERE nation_code = 'KOR';
/* The two transactions lock different objects
* and they do not block each-other.
*/
|
csql> DELETE FROM lock_tbl WHERE nation_code = 'GER';
|
csql> DELETE FROM lock_tbl WHERE host_year=2008;
/* T1 want's to modify a row locked by T2 and is blocked */
|
|
csql> DELETE FROM lock_tbl WHERE host_year = 2004;
/* T2 now want to delete the row blocked by T1
* and a deadlock is created.
*/
|
|
ERROR: Your transaction (index 1, dba@ 090205|4760)
has been unilaterally aborted by the system.
/* System rolled back the transaction 1 to resolve a deadlock */
|
/* T2 is unblocked and proceeds on modifying its rows. */
|
Transaction Lock Timeout¶
CUBRID provides the lock timeout feature, which sets the waiting time for the lock until the transaction lock setting is allowed.
If the lock is allowed within the lock timeout, CUBRID rolls back the transaction and outputs an error message when the timeout has passed. If a transaction deadlock occurs within the lock timeout, CUBRID rolls back the transaction whose waiting time is closest to the timeout.
Setting the Lock Timeout
The system parameter lock_timeout in the $CUBRID/conf/cubrid.conf file or the SET TRANSACTION statement sets the timeout (in seconds) during which the application will wait for the lock and rolls back the transaction and outputs an error message when the specified time has passed. The default value of the lock_timeout parameter is -1, which means the application will wait indefinitely until the transaction lock is allowed. Therefore, the user can change this value depending on the transaction pattern of the application. If the lock timeout value has been set to 0, an error message will be displayed as soon as a lock occurs.
SET TRANSACTION LOCK TIMEOUT timeout_spec [ ; ]
timeout_spec:
- INFINITE
- OFF
- unsigned_integer
- variable
- INFINITE : Wait indefinitely until the transaction lock is allowed. Has the same effect as setting the system parameter lock_timeout to -1.
- OFF : Do not wait for the lock, but roll back the transaction and display an error message. Has the same effect as setting the system parameter lock_timeout to 0.
- unsigned_integer : Set in seconds. Wait for the transaction lock for the specified time period.
- variable : A variable can be specified. Wait for the transaction lock for the value stored by the variable.
Example 1
vi $CUBRID/conf/cubrid.conf
...
lock_timeout = 10s
...
Example 2
SET TRANSACTION LOCK TIMEOUT 10;
Checking the Lock Timeout
You can check the lock timeout set for the current application by using the GET TRANSACTION statement, or store this value in a variable.
GET TRANSACTION LOCK TIMEOUT [ { INTO | TO } variable ] [ ; ]
Example
GET TRANSACTION LOCK TIMEOUT;
Result
===============
1.000000e+001
Checking and Handling Lock Timeout Error Message
The following message is displayed if lock timeout occurs in a transaction that has been waiting for another transaction's lock to be released.
Your transaction (index 2, user1@host1|9808) timed out waiting on IX_LOCK lock on class tbl. You are waiting for
user(s) user1@host1|csql(9807), user1@host1|csql(9805) to finish.
- Your transaction(index 2 ...): This means that the index of the transaction that was rolled back due to timeout while waiting for the lock is 2. The transaction index is a number that is sequentially assigned when the client connects to the database server. You can also check this number by executing the cubrid lockdb utility.
- (... user1@host1|9808): cub_user is the login ID of the client and the part after @ is the name of the host where the client was running. The part after| is the process ID (PID) of the client.
- IX_LOCK: This means the exclusive lock set on the object to perform data update. For details, see Lock Mode Types And Compatibility.
- user1@host1|csql(9807), user1@host1|csql(9805): Another transactions waiting for termination to lock IX_LOCK
That is, the above lock error message can be interpreted as meaning that "Because another client is holding X_LOCK on a specific row in the participant table, transaction 3 which running on the host host1 waited for the lock and the timeout has passed". If you want to check the lock information of the transaction specified in the error message, you can do so by using the cubrid lockdb utility to search for the OID value (ex: 0|636|34) of a specific row where the X_LOCK is set currently to find the transaction ID currently holding the lock, the client program name and the process ID (PID). For details, see lockdb. You can also check the transaction lock information in the CUBRID Manager.
You can organize the transactions by checking uncommitted queries through the SQL log after checking the transaction lock information in the manner described above. For information on checking the SQL log, see Broker Logs.
Also, you can forcefully stop problematic transactions by using the cubrid killtran utility. For details, see killtran.
Transaction Isolation Level¶
The transaction isolation level is determined based on how much interference occurs. The higher isolation means the less interference from other transactions and more serializable. The lower isolation means the more interference from other transactions and higher level of concurrency. You can control the level of consistency and concurrency specific to a service by setting appropriate isolation level.
Note
A transaction can be restored in all supported isolation levels because updates are not committed before the end of the transaction.
SET TRANSACTION ISOLATION LEVEL¶
You can set the level of transaction isolation by using isolation_level and the SET TRANSACTION statement in the $CUBRID/conf/cubrid.conf. The level of READ COMMITTED is set by default, which indicates the level 4 through level 4 to 6 (levels 1 to 3 were used by older versions of CUBRID and are now obsolete). For details, see Database Concurrency.
SET TRANSACTION ISOLATION LEVEL isolation_level_spec ;
isolation_level_spec:
SERIALIZABLE | 6
REPETABLE READ | 5
READ COMMITTED | CURSOR STABILITY | 4
Example 1
vi $CUBRID/conf/cubrid.conf
...
isolation_level = 4
...
-- or
isolation_level = "TRAN_READ_COMMITTED"
Example 2
SET TRANSACTION ISOLATION LEVEL 4;
-- or
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
Levels of Isolation Supported by CUBRID
| Name | Description |
|---|---|
| READ COMMITTED (4) | Another transaction T2 cannot update the schema of table A while transaction T1 is viewing table A. Transaction T1 may experience R read (non-repeatable read) that was updated and committed by another transaction T2 when it is repeatedly retrieving the record R. |
| REPEATABLE READ (5) | Another transaction T2 cannot update the schema of table A while transaction T1 is viewing table A. Transaction T1 may experience phantom read for the record R that was inserted by another transaction T2 when it is repeatedly retrieving a specific record. |
| SERIALIZABLE (6) | Temporarily disabled - details in SERIALIZABLE Isolation Level |
If the transaction level is changed in an application while a transaction is executed, the new level is applied to the rest of the transaction being executed. It is recommended that to modify the transaction isolation level when a transaction starts (after commit, rollback or system restart) because an isolation level which has already been set does not apply to the entire transaction, but can be changed during the transaction.
GET TRANSACTION ISOLATION LEVEL¶
You can assign the current isolation level to variable by using the GET TRANSACTION ISOLATION LEVEL statement. The following is a statement that verifies the isolation level.
GET TRANSACTION ISOLATION LEVEL [ { INTO | TO } variable ] [ ; ]
GET TRANSACTION ISOLATION LEVEL;
Result
=============
READ COMMITTED
READ COMMITTED Isolation Level¶
A relatively low isolation level (4). A dirty read does not occur, but non-repeatable or phantom read may. That is, transaction T1 can read another value because insert or update by transaction T2 is allowed while transaction T1 is repeatedly retrieving one object.
The following are the rules of this isolation level:
- Transaction T1 cannot read or modify the record inserted by another transaction T2. The record is instead ignored.
- Transaction T1 can read the record being updated by another transaction T2 and it sees the record's last committed version (but it cannot see uncommitted versions).
- Transaction T1 cannot modify the record being updated by another transaction T2. T1 waits for T2 to commit and it re-evaluates record values. If the re-evaluation test is passed, T1 modifies the record, otherwise it ignores it.
- Transaction T1 can modify the record being viewed by another transaction T2.
- Transaction T1 can update/insert record to the table being viewed by another transaction T2.
- Transaction T1 cannot change the schema of the table being viewed by another transaction T2.
- Transaction T1 creates a new snapshot with each executed statement, thus phantom or non-repeatable read may occur.
This isolation level follows MVCC locking protocol for an exclusive lock. A shared lock on a row is not required; however, an intent lock on a table is released when a transaction terminates to ensure repeatable read on the schema.
Example
The following example shows that a phantom or non-repeatable read may occur because another transaction can add or update a record while one transaction is performing the object read but repeatable read for the table schema update is ensured when the transaction level of the concurrent transactions is READ COMMITTED.
| session 1 | session 2 |
|---|---|
csql> ;autocommit off
AUTOCOMMIT IS OFF
csql> SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
Isolation level set to:
READ COMMITTED
|
csql> ;autocommit off
AUTOCOMMIT IS OFF
csql> SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
Isolation level set to:
READ COMMITTED
|
csql> CREATE TABLE isol4_tbl(host_year integer, nation_code char(3));
csql> INSERT INTO isol4_tbl VALUES (2008, 'AUS');
csql> COMMIT;
|
|
csql> SELECT * FROM isol4_tbl;
host_year nation_code
===================================
2008 'AUS'
|
|
csql> INSERT INTO isol4_tbl VALUES (2004, 'AUS');
csql> INSERT INTO isol4_tbl VALUES (2000, 'NED');
csql> COMMIT;
|
|
/* phantom read occurs because tran 1 committed */
csql> SELECT * FROM isol4_tbl;
host_year nation_code
===================================
2008 'AUS'
2004 'AUS'
2000 'NED'
|
|
csql> UPDATE isol4_tbl
csql> SET nation_code = 'KOR'
csql> WHERE host_year = 2008;
csql> COMMIT;
|
|
/* unrepeatable read occurs because tran 1 committed */
csql> SELECT * FROM isol4_tbl;
host_year nation_code
===================================
2008 'KOR'
2004 'AUS'
2000 'NED'
|
|
csql> ALTER TABLE isol4_tbl ADD COLUMN gold INT;
/* unable to alter the table schema until tran 2 committed */
|
|
/* repeatable read is ensured while
* tran_1 is altering table schema
*/
csql> SELECT * FROM isol4_tbl;
host_year nation_code
===================================
2008 'KOR'
2004 'AUS'
2000 'NED'
|
|
csql> COMMIT;
|
|
csql> SELECT * FROM isol4_tbl;
/* unable to access the table until tran_1 committed */
|
|
csql> COMMIT;
|
|
host_year nation_code gold
===================================
2008 'KOR' NULL
2004 'AUS' NULL
2000 'NED' NULL
|
READ COMMITTED UPDATE RE-EVALUATION¶
READ COMMITTED isolation treats concurrent row updates differently than higher isolation levels. In higher isolation levels, if T2 tries to modify a row already updated by concurrent transaction T1, it is blocked until T1 commits and rollbacks, and if T1 commits, T2 aborts its statement execution, throwing serialization error. Under READ COMMITTED isolation, after T1 commits, T2 does not immediately abort its statement execution and re-evaluates the new version, which is not considered committed and would not violate any restrictions for this isolation. If the predicate used to select previous version is still true for the new version, T2 goes ahead and modifies the new version. If the predicate is no longer true, T2 just ignores the record as if the predicate was never satisfied.
Example:
| session 1 | session 2 |
|---|---|
csql> ;autocommit off
AUTOCOMMIT IS OFF
csql> SET TRANSACTION ISOLATION LEVEL 4;
Isolation level set to:
READ COMMITTED
|
csql> ;autocommit off
AUTOCOMMIT IS OFF
csql> SET TRANSACTION ISOLATION LEVEL 4;
Isolation level set to:
READ COMMITTED
|
csql> CREATE TABLE isol4_tbl(host_year integer, nation_code char(3));
csql> INSERT INTO isol4_tbl VALUES (2000, 'KOR');
csql> INSERT INTO isol4_tbl VALUES (2004, 'USA');
csql> INSERT INTO isol4_tbl VALUES (2004, 'GER');
csql> INSERT INTO isol4_tbl VALUES (2008, 'GER');
csql> COMMIT;
|
|
csql> UPDATE isol4_tbl
csql> SET host_year = host_year - 4
csql> WHERE nation_code = 'GER';
/* T1 locks and modifies (2004, 'GER') to (2000, 'GER') */
/* T1 locks and modifies (2008, 'GER') to (2004, 'GER') */
|
|
csql> UPDATE isol4_tbl
csql> SET host_year = host_year + 4
csql> WHERE host_year >= 2004;
/* T2 snapshot will try to modify three records:
* (2004, 'USA'), (2004, 'GER'), (2008, 'GER')
*
* T2 locks and modifies (2004, 'USA') to (2008, 'USA')
* T2 is blocked on lock on (2004, 'GER').
*/
|
|
csql> COMMIT;
/* T1 releases locks on modified rows. */
|
|
/* T2 is unblocked and will do the next steps:
*
* T2 finds (2004, 'GER') has a new version (2000, 'GER')
* that doesn't satisfy predicate anymore.
* T2 releases the lock on object and ingores it.
*
* T2 finds (2008, 'GER') has a new version (2004, 'GER')
* that still satisfies the predicate.
* T2 keeps the lock and changes row to (2008, 'GER')
*/
|
|
csql> SELECT * FROM isol4_tbl;
host_year nation_code
===================================
2000 'KOR'
2000 'GER'
2008 'USA'
2008 'GER'
|
REPEATABLE READ Isolation Level¶
A relatively high isolation level (5). Dirty, non-repeatable, and phantom reads do not occur due to snapshot isolation. However, it's still not truly serializable, transaction execution cannot be defined as if there were no other transactions running at the same time. More complex anomalies, like write skews, that a serializable snapshot isolation level should not allow still occur.
In a write skew anomaly, two transactions concurrently read overlapping data sets and make disjoint updates on the overlapped data set, neither having seen the update performed by the other. In a serializable system, such anomaly would be impossible, since one transaction must occur first and the second transaction should see the update of the first transaction.
The following are the rules of this isolation level:
- Transaction T1 cannot read or modify the record inserted by another transaction T2. The record is instead ignored.
- Transaction T1 can read the record being updated by another transaction T2 and it will see the record's last committed version.
- Transaction T1 cannot modify the record being updated by another transaction T2.
- Transaction T1 can modify the record being viewed by another transaction T2.
- Transaction T1 can update/insert record to the table being viewed by another transaction T2.
- Transaction T1 cannot change the schema of the table being viewed by another transaction T2.
- Transaction T1 creates a unique snapshot valid throughout the entire duration of the transaction.
Example
The following example shows that non-repeatable and phantom reads may not occur because of snapshot isolation. However, write skews are possible, which means the isolation level is not serializable.
| session 1 | session 2 |
|---|---|
csql> ;autocommit off
AUTOCOMMIT IS OFF
csql> SET TRANSACTION ISOLATION LEVEL 5;
Isolation level set to:
REPEATABLE READ
|
csql> ;autocommit off
AUTOCOMMIT IS OFF
csql> SET TRANSACTION ISOLATION LEVEL 5;
Isolation level set to:
REPEATABLE READ
|
csql> CREATE TABLE isol5_tbl(host_year integer, nation_code char(3));
csql> CREATE UNIQUE INDEX isol5_u_idx
on isol5_tbl(nation_code, host_year);
csql> INSERT INTO isol5_tbl VALUES (2008, 'AUS');
csql> INSERT INTO isol5_tbl VALUES (2004, 'AUS');
csql> COMMIT;
|
|
csql> SELECT * FROM isol5_tbl WHERE nation_code='AUS';
host_year nation_code
===================================
2004 'AUS'
2008 'AUS'
|
|
csql> INSERT INTO isol5_tbl VALUES (2004, 'KOR');
csql> INSERT INTO isol5_tbl VALUES (2000, 'AUS');
/* able to insert new rows */
csql> COMMIT;
|
|
csql> SELECT * FROM isol5_tbl WHERE nation_code='AUS';
/* phantom read connot occur due to snapshot isolation */
host_year nation_code
===================================
2004 'AUS'
2008 'AUS'
|
|
csql> UPDATE isol5_tbl
csql> SET host_year = 2012
csql> WHERE nation_code = 'AUS' and
csql> host_year=2008;
/* able to update rows viewed by T2 */
csql> COMMIT;
|
|
csql> SELECT * FROM isol5_tbl WHERE nation_code = 'AUS';
/* non-repeatable read cannot occur due to snapshot isolation */
host_year nation_code
===================================
2004 'AUS'
2008 'AUS'
|
|
csql> COMMIT;
|
|
csql> SELECT * FROM isol5_tbl WHERE host_year >= 2004;
host_year nation_code
===================================
2004 'AUS'
2004 'KOR'
2012 'AUS'
csql> UPDATE isol5_tbl
csql> SET nation_code = 'USA'
csql> WHERE nation_code = 'AUS' and
csql> host_year = 2004;
csql> COMMIT;
|
csql> SELECT * FROM isol5_tbl WHERE nation_code = 'AUS';
host_year nation_code
===================================
2000 'AUS'
2004 'AUS'
2012 'AUS'
csql> UPDATE isol5_tbl
csql> SET nation_code = 'NED'
csql> WHERE nation_code = 'AUS' and
csql> host_year = 2012;
csql> COMMIT;
|
/* T1 and T2 first have selected each 3 throws and rows (2004, 'AUS'), (2012, 'AUS') overlapped.
* Then T1 modified (2004, 'AUS'), while T2 modified (2012, 'AUS'), without blocking each other.
* In a serial execution, the result of select query for T1 or T2, whichever executes last, would be different.
*/
|
|
csql> SELECT * FROM isol5_tbl WHERE nation_code = 'AUS';
host_year nation_code
===================================
2000 'AUS'
|
|
csql> ALTER TABLE isol5_tbl ADD COLUMN gold INT;
/* unable to alter the table schema until tran 2 committed */
|
|
/* repeatable read is ensured while tran_1 is altering
* table schema
*/
csql> SELECT * FROM isol5_tbl WHERE nation_code = 'AUS';
host_year nation_code
===================================
2000 'AUS'
|
|
csql> COMMIT;
|
|
csql> SELECT * FROM isol5_tbl WHERE nation_code = 'AUS';
/* unable to access the table until tran_1 committed */
|
|
csql> COMMIT;
|
|
host_year nation_code gold
===================================
2000 'AUS' NULL
|
|
SERIALIZABLE Isolation Level¶
CUBRID 10.0 SERIALIZABLE isolation level is identical to REPEATABLE READ isolation level. As explained in REPEATABLE READ Isolation Level section, even though SNAPSHOT isolation ensures non-repeatable read and phantom read anomalies do not happen, write skew anomalies are still possible. To protect against write skew, index key locks for read may be used. Alternatively, there are many works that describe complex systems to provide SERIALIZABLE SNAPSHOT ISOLATION, by aborting transactions with the potential of creating an isolation conflict. One such system will be provided in a future CUBRID version.
The keyword was not removed for backward compatibility reasons, but remember, it is similar to REPEATABLE READ.
How to Handle Dirty Record¶
CUBRID flushes dirty data (or dirty record) in the client buffers to the database (server) such as the following situations. In additions to those, there can be more situations where flushes can be performed.
- Dirty data can be flushed to server when a transaction is committed.
- Some of dirty data can be flushed to server when a lot of data is loaded into the client buffers.
- Dirty data of table A can be flushed to server when the schema of table A is updated.
- Dirty data of table A can be flushed to server when the table A is retrieved (SELECT)
- Some of dirty data can be flushed to server when a server function is called.
Transaction Termination and Restoration¶
The restore process in CUBRID makes it possible that the database is not affected even if a software or hardware error occurs. In CUBRID, all read and update commands that are made during a transaction must be atomic. This means that either all of the transaction's commands are committed to the database or none are. The concept of atomicity is extended to the set of operations that consists of a transaction. The transaction must either commit so that all effects are permanently applied to the database or roll back so that all effects are removed. To ensure transaction atomicity, CUBRID applies the effects of the committed transaction again every time an error occurs without the updates of the transaction being written to the disk. CUBRID also removes the effects of partially committed transactions in the database every time the site fails (some transactions may have not committed or applications may have requested to cancel transactions). This restore feature eases the burden for the applications of maintaining the database consistency depending on the system error. The restore process used in CUBRID is based on the undo/redo logging mechanism.
CUBRID provides an automatic restore method to maintain the transaction atomicity when a hardware or software error occurs. You do not have to take the responsibility for restore since CUBRID's restore feature always returns the database to a consistent state even when an application or computer system error occurs. For this purpose, CUBRID automatically rolls back part of committed transactions when the application fails or the user requests explicitly. For example, a system error that occurred during the execution of the COMMIT WORK statement must be stopped if the transaction has not committed yet (it cannot be confirmed that the user's operation has been committed). Automatic stop prevents errors causing undesired changes to the database by canceling uncommitted updates.
Restarting Database¶
CUBRID uses log volumes/files and database backups to restore committed or uncommitted transactions when system or media (disk) error occurs. Logs are also used to support the user-specified rollback. A log consists of a collection of sequential files created by CUBRID. The most recent log is called the active log, and the rest are called archive logs. A log file refers to both the active and archive logs.
All updates of the database are written to the log. Actually, two copies of the updates are logged. The first one is called a before image (UNDO log) and used to restore data during execution of the user-specified ROLLBACK WORK statement or during media or system errors. The second copy is an after image (REDO log) and used to re-apply the updates when media or system error occurs.
When the active log is full, CUBRID copies it to an archive log to store in the disk. The archive log is needed to restore the database when a system failure occurs.
Normal Termination or Error
CUBRID restores the database if it restarts due to a normal termination or a device error. The restore process re-applies the committed changes that have not been applied to the database and removes the uncommitted changes stored in the database. The general operation of the database resumes after the restore is completed. This restore process does not use any archive logs or database backup.
In a client/server environment, the database can restart by using the cubrid server utility.
Media Error
The user's intervention is somewhat needed to restart the database after media error occurs. The first step is to restore the database by installing a backup of a known good state. In CUBRID, the most recent log file (the one after the last backup) must be installed. This specific log (archive or active) is applied to a backup copy of the database. As with normal termination, the database can restart after restoration is committed.
Note
To minimize the possibility of losing database updates, it is recommended to create a snapshot and store it in the backup media before it is deleted from the disk. The DBA can backup and restore the database by using the cubrid backupdb and cubrid restoredb utilities. For details on these utilities, see backupdb.